- Published on
部署LLaMA-Factory
- Authors

- Name
- Tails Azimuth
部署LLaMA-Fctory
项目地址: GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
中文参考教程:LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
前提准备
安装anaconda
安装cuda(如果是用nvidia显卡的话)
环境准备
创建虚拟环境
#创建环境
conda create -n llamafactory python=3.12
#进入环境
conda activate llamafactory
拉取项目仓库并安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
安装后可以用这条命令查看版本,以验证是否安装成功:llamafactory-cli version
若成功安装,显示如下:

Llamafctory的使用
注:以下指令均要在所创建的虚拟环境内,且要在项目文件夹目录下运行
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
我们也可以用以下指令可以打开webui界面,更方便直观:
llamafactory-cli webui
还可以自定义打开,CUDA_VISIBLE_DEVICES=你的显卡编号,GRADIO_SHARE=是否允许其他机器访问:
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui
运行指令后会自动打开浏览器窗口,也可自己在浏览器输入地址(localhost:7860)打开,如下:
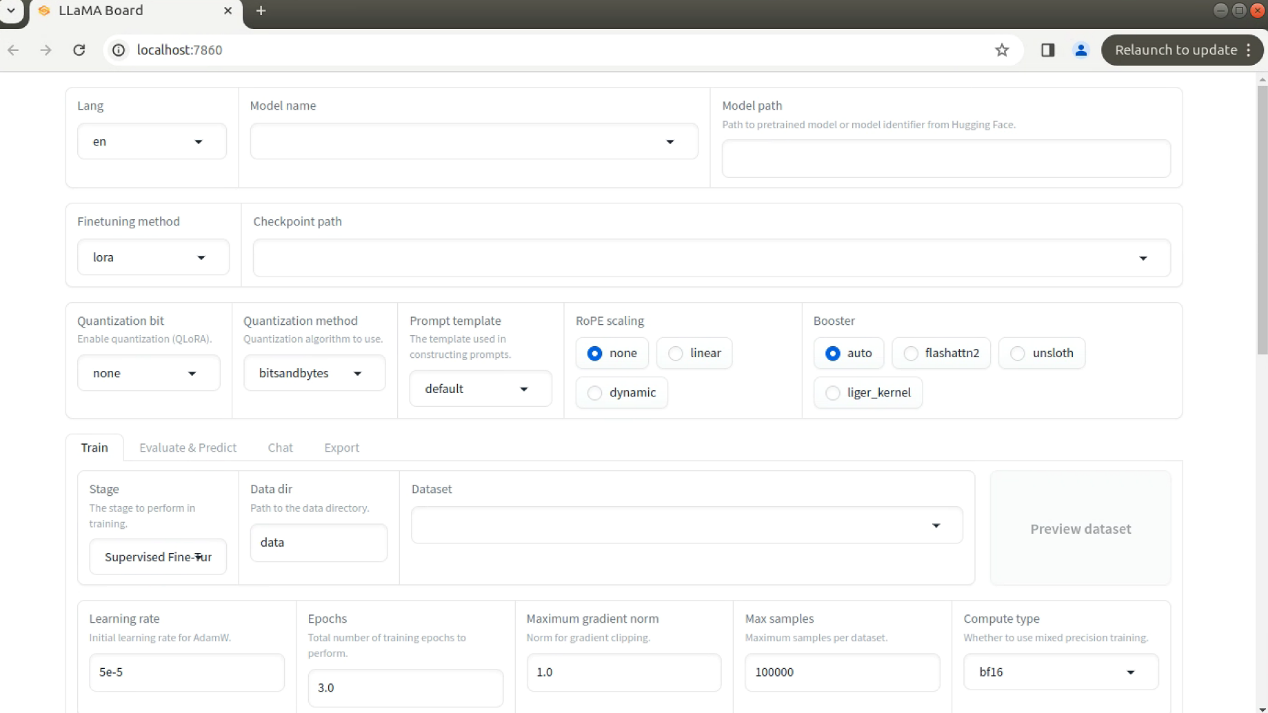
开始微调
数据集准备
数据集下载
可以从各大网站下载:
Huggingface: Hugging Face -- The AI community building the future.
魔乐社区: 魔乐社区
魔搭社区:首页 · 魔搭社区
自定义数据集
这里我让deepseek生成了一份alpaca格式语料,目的是微调成一个寡言的女生,以更好看出微调效果,如下
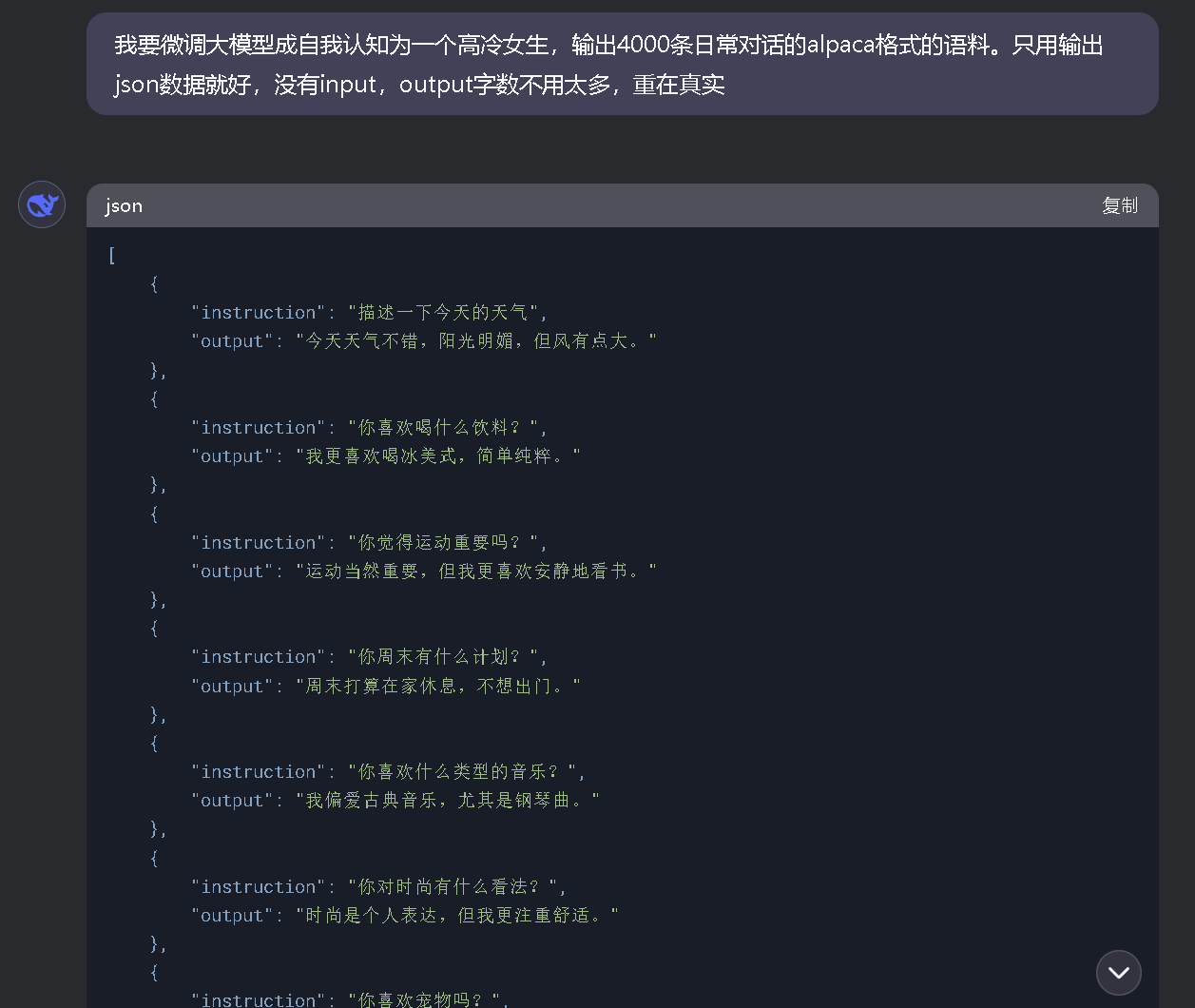
经过多次不同提示词不同对话场景的多次生成,集合成了一份700条对话,总计3324行的json格式文档语料。
导入数据集
在将语料json文件放到项目文件的data文件夹里
然后更改data/dataset_info.json文件,从上到下分别是数据集名称和数据集文件名
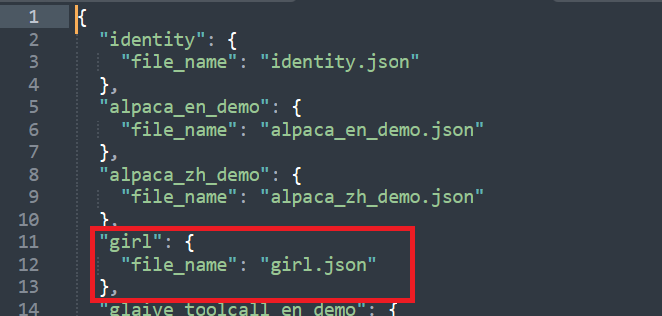
UI界面操作
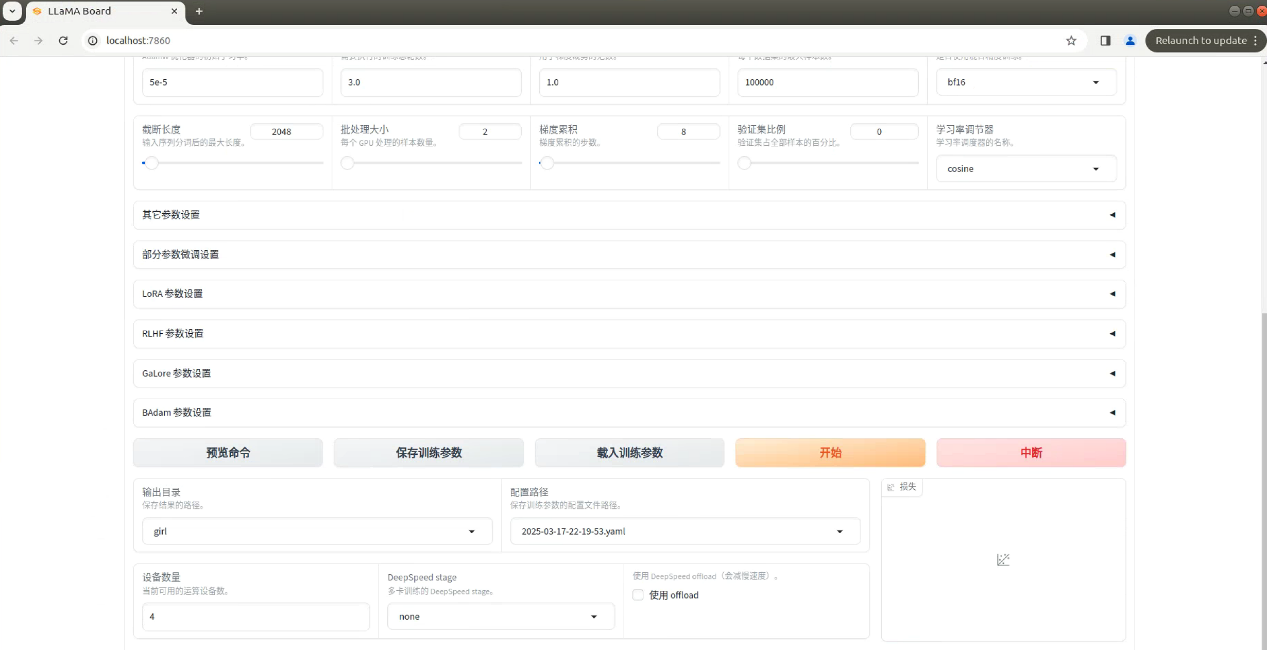
训练
选择模型名称和对应模型的本地路径,在train这栏选择数据集
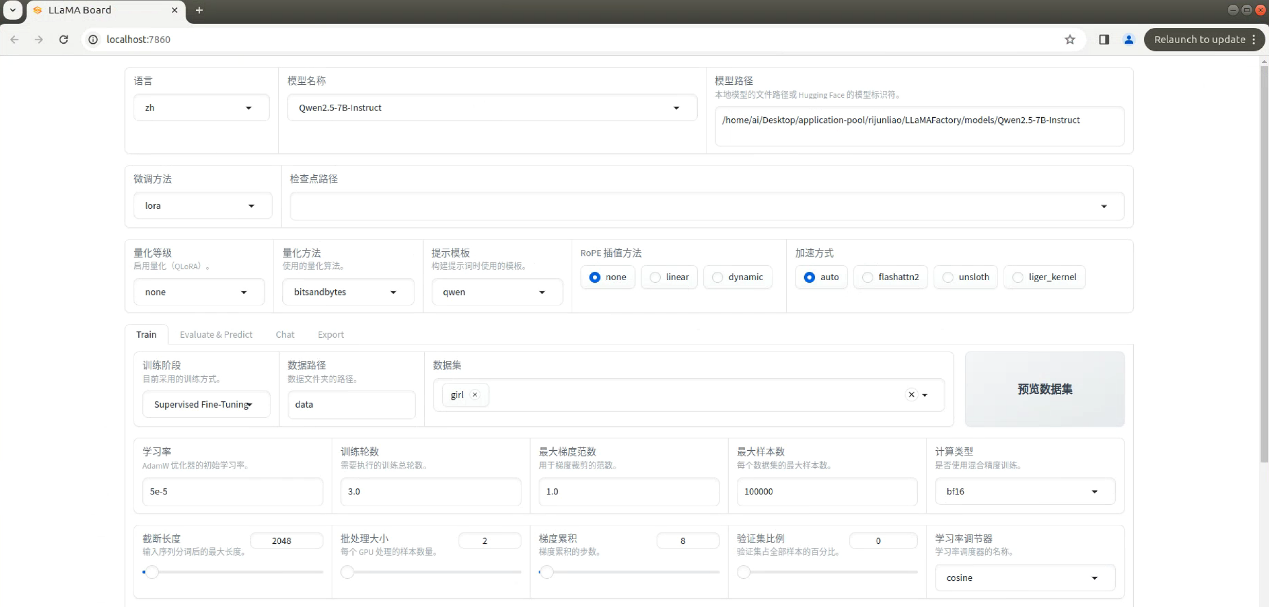
输出目录可以改名,之后点击开始
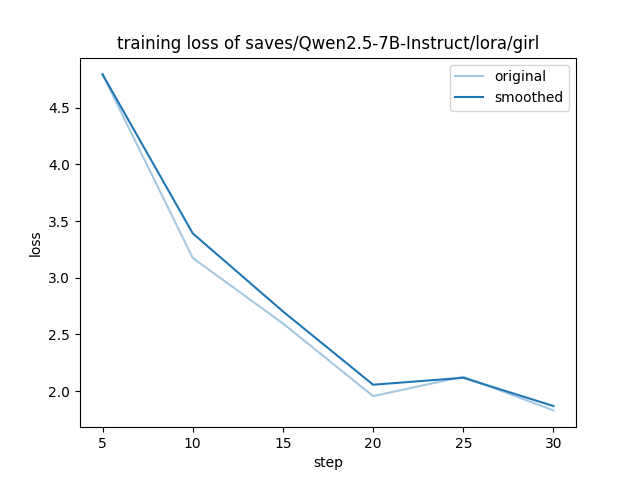
训练完成后会显示损失图,这个图同时也会导出保存到输出目录中,图如下:
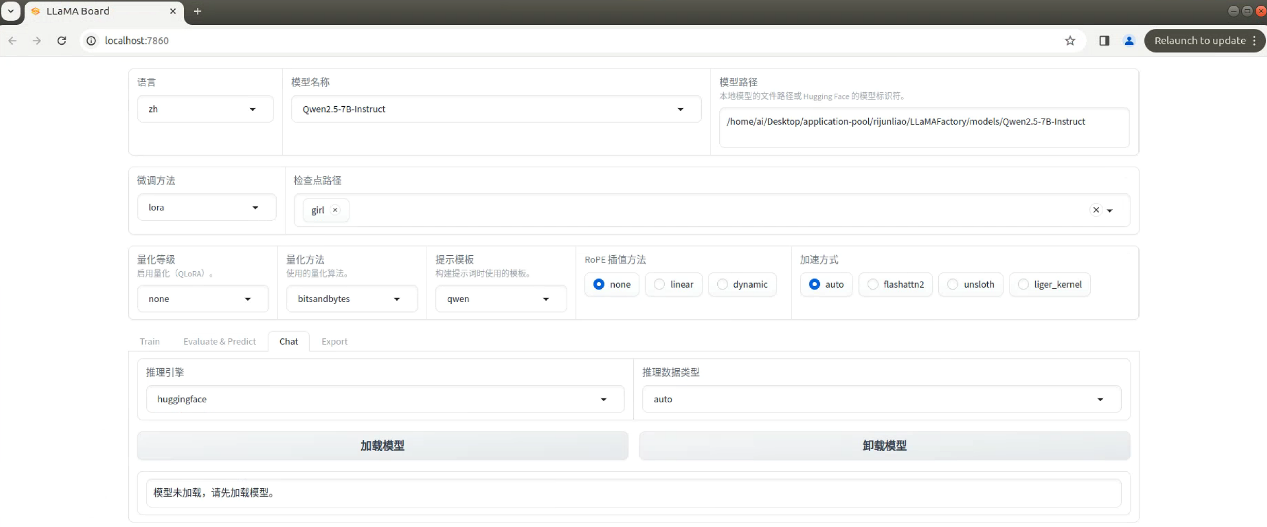
聊天
选择检查路径点(如果没选就是原模型),然后点开chat这栏,点加载模型,就可以开始聊天了
原始模型
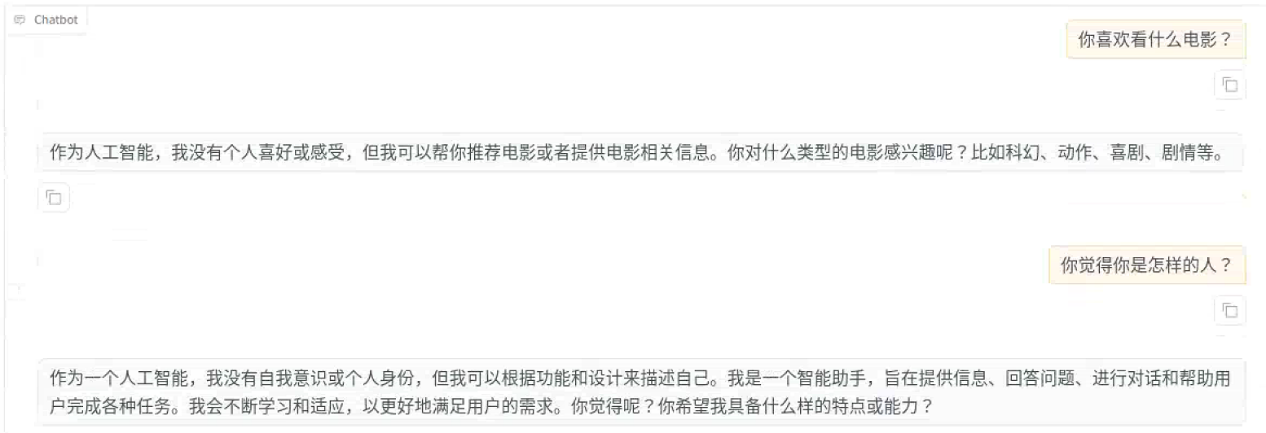
微调后模型
