- Published on
本地部署LightRAG
- Authors

- Name
- Tails Azimuth
本地部署LightRAG
项目地址:HKUDS/LightRAG: "LightRAG: Simple and Fast Retrieval-Augmented Generation"
官方视频:Local LightRAG: A GraphRAG Alternative but Fully Local with Ollama
参考视频:全面超越GraphRAG,速度更快,效果更好,落地部署更方便。从原理、本地Qwen2.5-3B模型部署到源码解读,带你全流程解析LightRAG_哔哩哔哩_bilibili
将项目拉到本地文件夹:git clone https://github.com/HKUDS/LightRAG.git
创建新环境lightrag(python==3.10.13)
安装依赖:项目文件夹打开终端,进入虚拟环境,执行pip install -e .
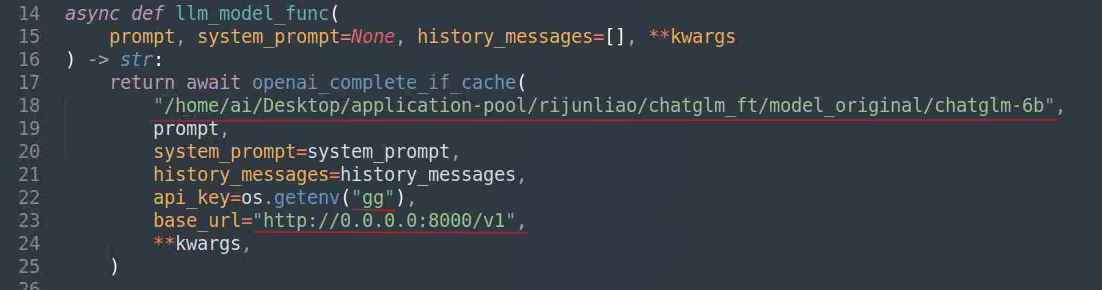
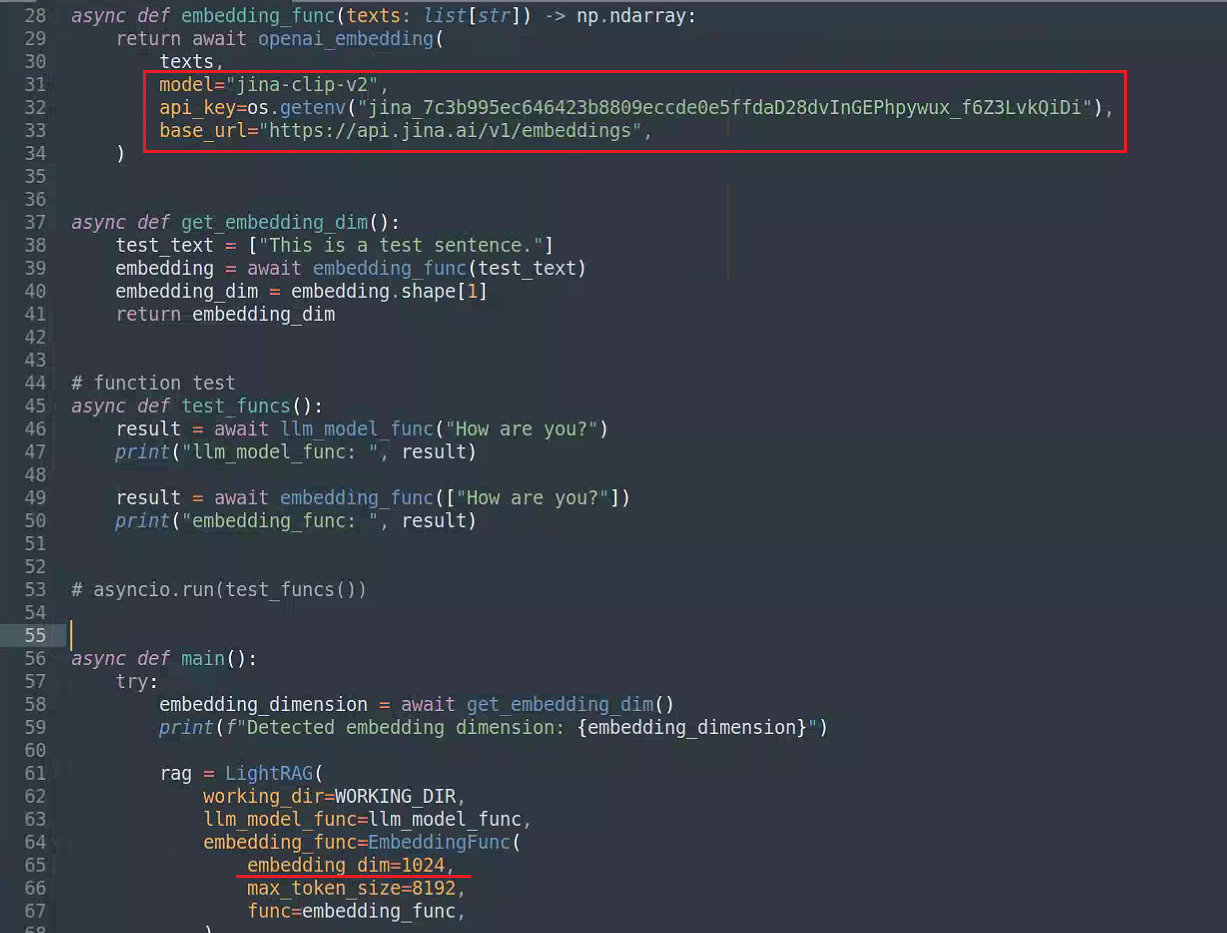
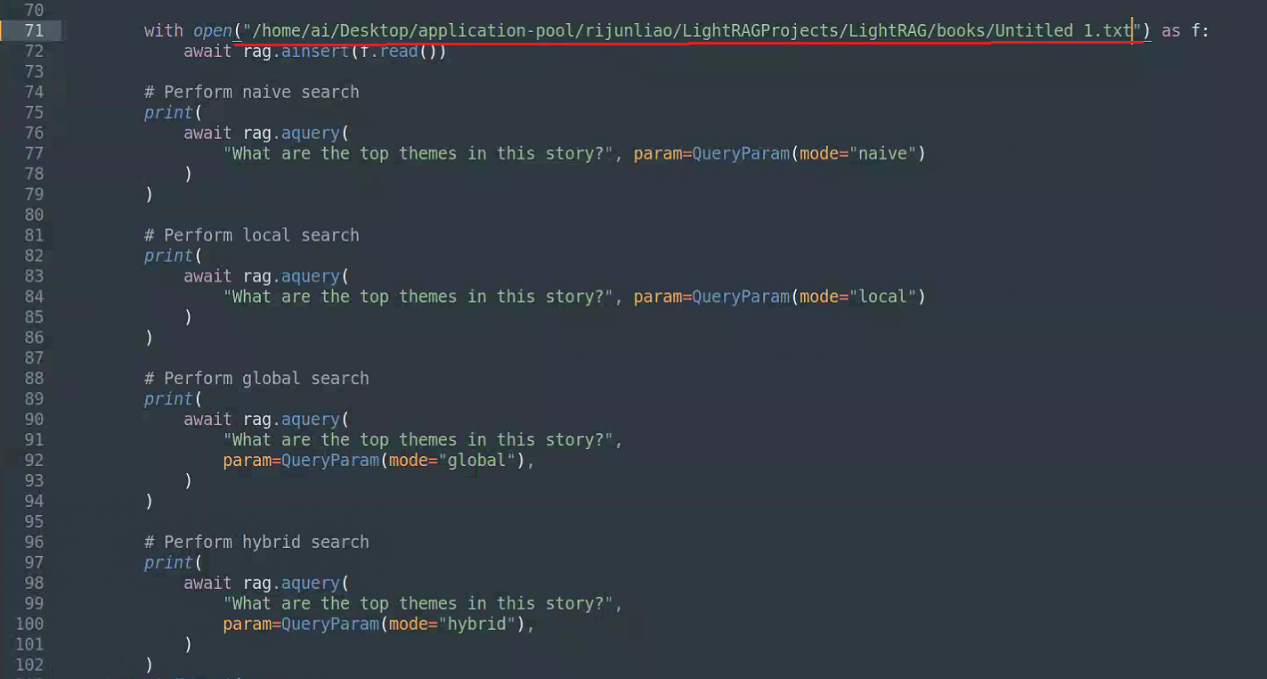
更改文件examples/lightrag_api_openai_compatible_demo.py里的配置:
Llm模型:
Embedding模型:
文本位置:
部署ollama
创建conda环境:python=3.10
到官网下载:https://ollama.com/
复制指令,开始下载
下载完成

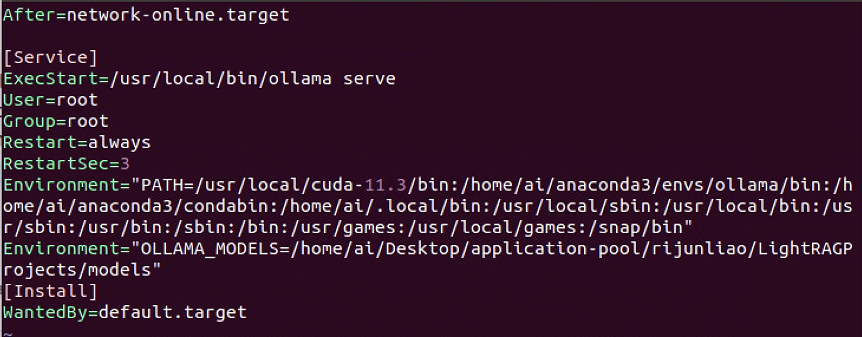
- 更改模型下载路径,参考:Ollama模型下载路径替换!靠谱!(Linux版本)_修改ollama模型路径-CSDN博客
更改后的配置:
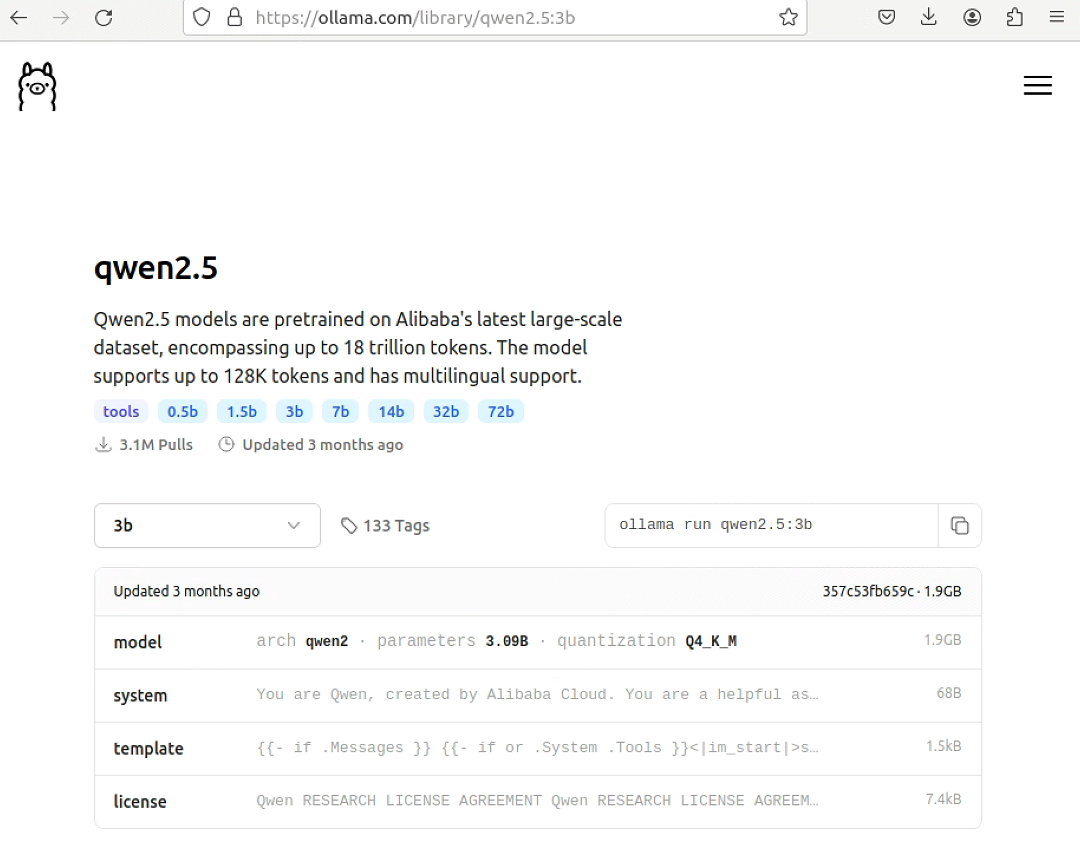
- 下载llm模型:
在ollma官网中找到对应的模型,我下的是qwen2.5:3b
复制运行指令(ollama run qwen2.5:3b)运行,若检测到本地没有该模型,会自动下载到本地
- 下载embedding模型,步骤如上,我下载的是bge-m3,输入指令:ollama pull bge-m3
Highlight of bge-m3:
BGE-M3支持超过100种语言的语义表示及检索任务,多语言、跨语言能力全面领先(Multi-Lingual)
BGE-M3最高支持8192长度的输入文本,高效实现句子、段落、篇章、文档等不同粒度的检索任务(Multi-Granularity)
BGE-M3同时集成了稠密检索、稀疏检索、多向量检索三大能力,一站式支撑不同语义检索场景(Multi-Functionality)
配置运行
参考视频:
Local LightRAG: A GraphRAG Alternative but Fully Local with Ollama - YouTube
LightRAG安装使用分享-知识图谱检索增强大语言模型能力-本地知识库_哔哩哔哩_bilibili
ollama部署LightRAG或GraphRAG的一个小小小坑,以及LightRAG最新可视化展示,html or neo4j_哔哩哔哩_bilibili
- 在lightrag项目文件下打开终端,进入lightrag虚拟环境,执行:ollama show --modelfile qwen2.5:3b > Modelfile,在项目文件中创建qwen2.5:3b的模型配置文件Modelfile,并在其中加入一行设定,将模型的最大上下文设为32k(因为大模型对上下文要求高,所以用默认的可能会导致不成功或效果不好),如下:
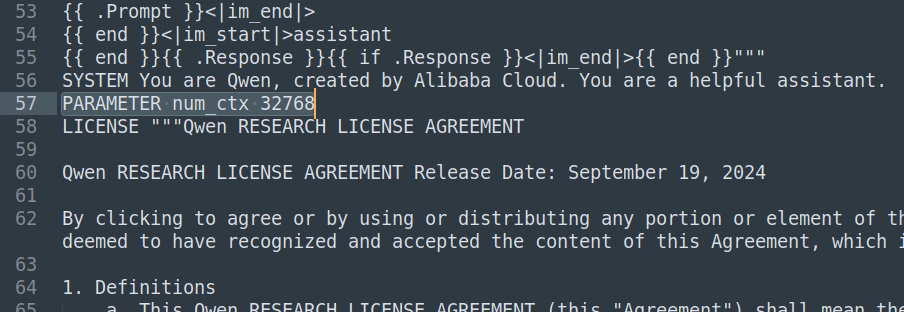
- 执行:ollama create -f Modelfile qwen2.5:3bm,创建一个新的配置,并命名为qwen2.5:3bm,这样就可以用这个名字直接运行该配置的模型。
可以看到模型目录里有了新创建的配置名称

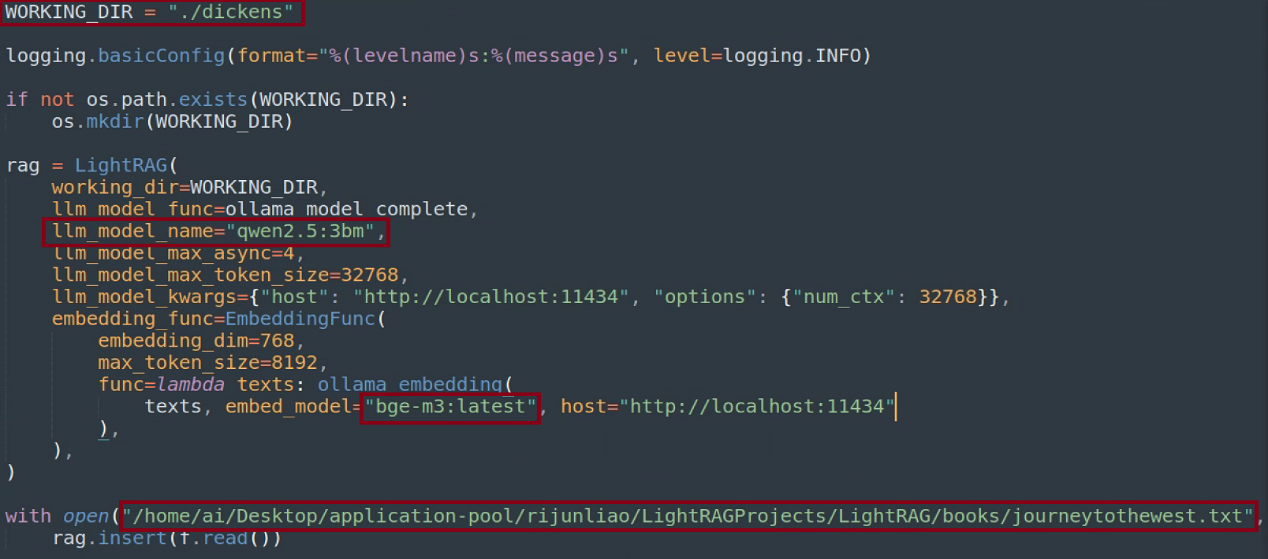
- 更改examples/lightrag_ollama_demo.py文件,从上到下分别是输出路径,运行的llm名称,embedding模型名称,提取的文本路径
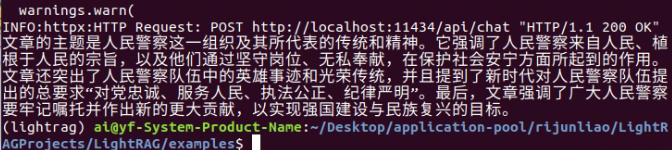
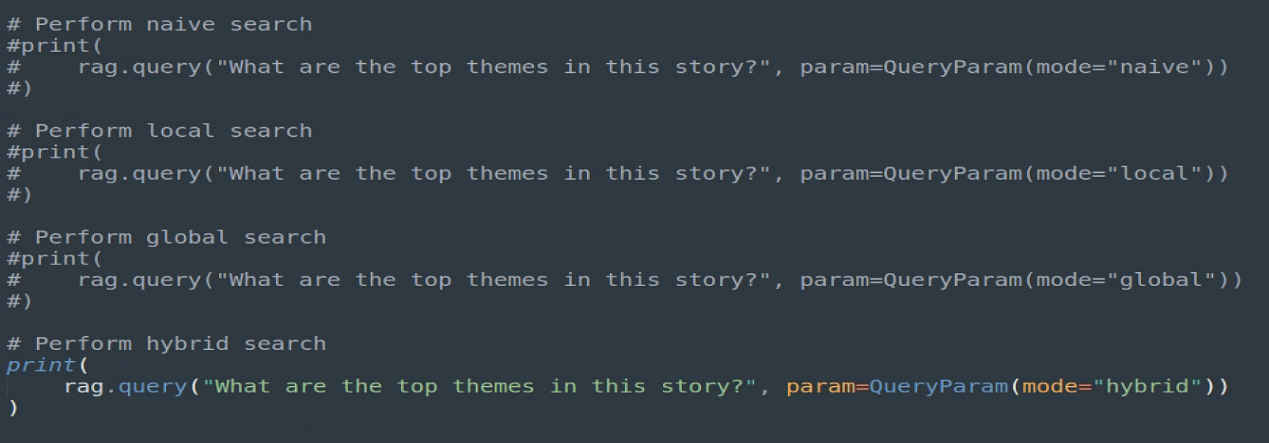
先试试仅用hybrid(混合)模式
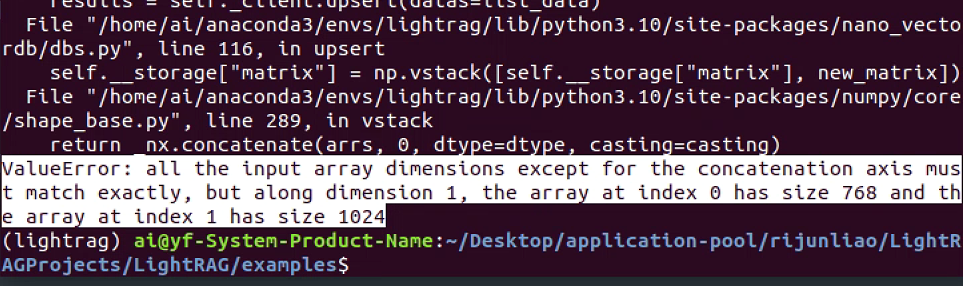
- 将llm和embedding模型都用ollama运行起来,然后运行修改好的lightrag_ollama_demo.py文件,报错:
试将更换一个embedding模型:nomic-embed-text,更改配置里的embedding名称,选一篇英语文章,再次运行成功:
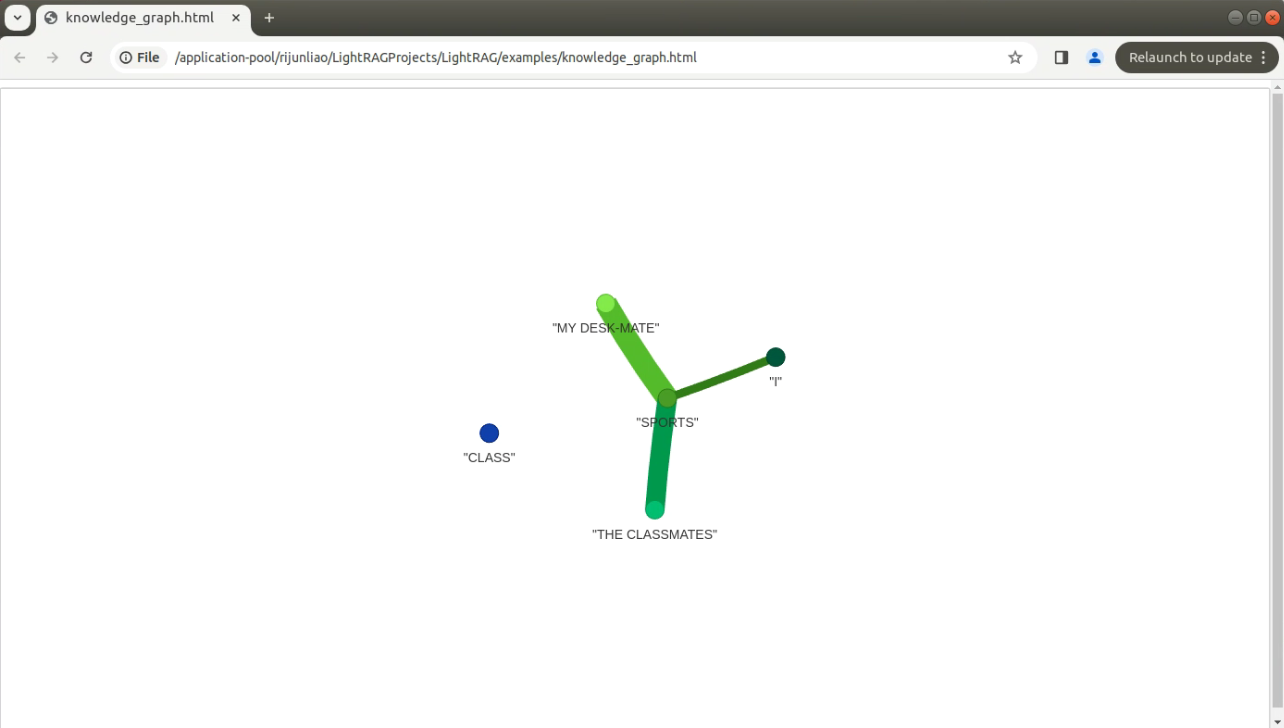
- 运行examples/graph_visual_with_html.py,会在example下生成一个html文件,打开如下:
(还可以通过运行examples/graph_visual_with_neo4j.py来生成关系图)
- 将examples/dickens文件夹里的文件先删掉,不然再次运行会叠加上次生成的内容;然后将输入的文本路径改为一个中文的文档,并在配置中用中文提问进行测试:
尝试生成关系图: